The Hidden Cost of On-Chain Data Latency on Sui and Hyperliquid
Many trading teams operating on Sui and Hyperliquid may not know how much on-chain data latency is costing them. Not because they are making bad decisions. Not because their strategies are flawed. Because the infrastructure baseline they are measuring against was never fast enough to begin with.
When every team in your market is working from the same delayed data feed, the cost of that delay becomes invisible. There is no benchmark to reveal it. No P&L line that says “latency loss.” The opportunity simply does not appear, and the team moves on, assuming the strategy underperformed.
This is the hidden cost of on-chain data latency. And on chains with sub-second finality like Sui and Hyperliquid, it is larger than most teams realize.
What on-chain data latency actually means
On-chain data latency is the gap between when something happens on the network and when your systems see it.
It sounds simple. In practice, it compounds across every layer of public infrastructure. A transaction is processed by a validator. Before it reaches your system, it has to propagate through the network, reach a public checkpoint or RPC endpoint, pass through shared infrastructure serving hundreds of other clients, and finally arrive at your stack. Each hop adds delay. Shared infrastructure adds queuing. Rate limits add throttling.
The result is that by the time your system sees the data, the network has moved on. Other teams have already acted. The window you were trying to trade is closed.
On Ethereum, where block times are measured in seconds, this gap is inconvenient but manageable. On Sui and Hyperliquid, where block times are measured in hundreds of milliseconds, the math changes entirely. A latency gap of 150 to 170 ms is not a rounding error on a chain that finalizes every 200 to 400 ms. It is the difference between seeing a state change before and after the next block.
The baseline problem
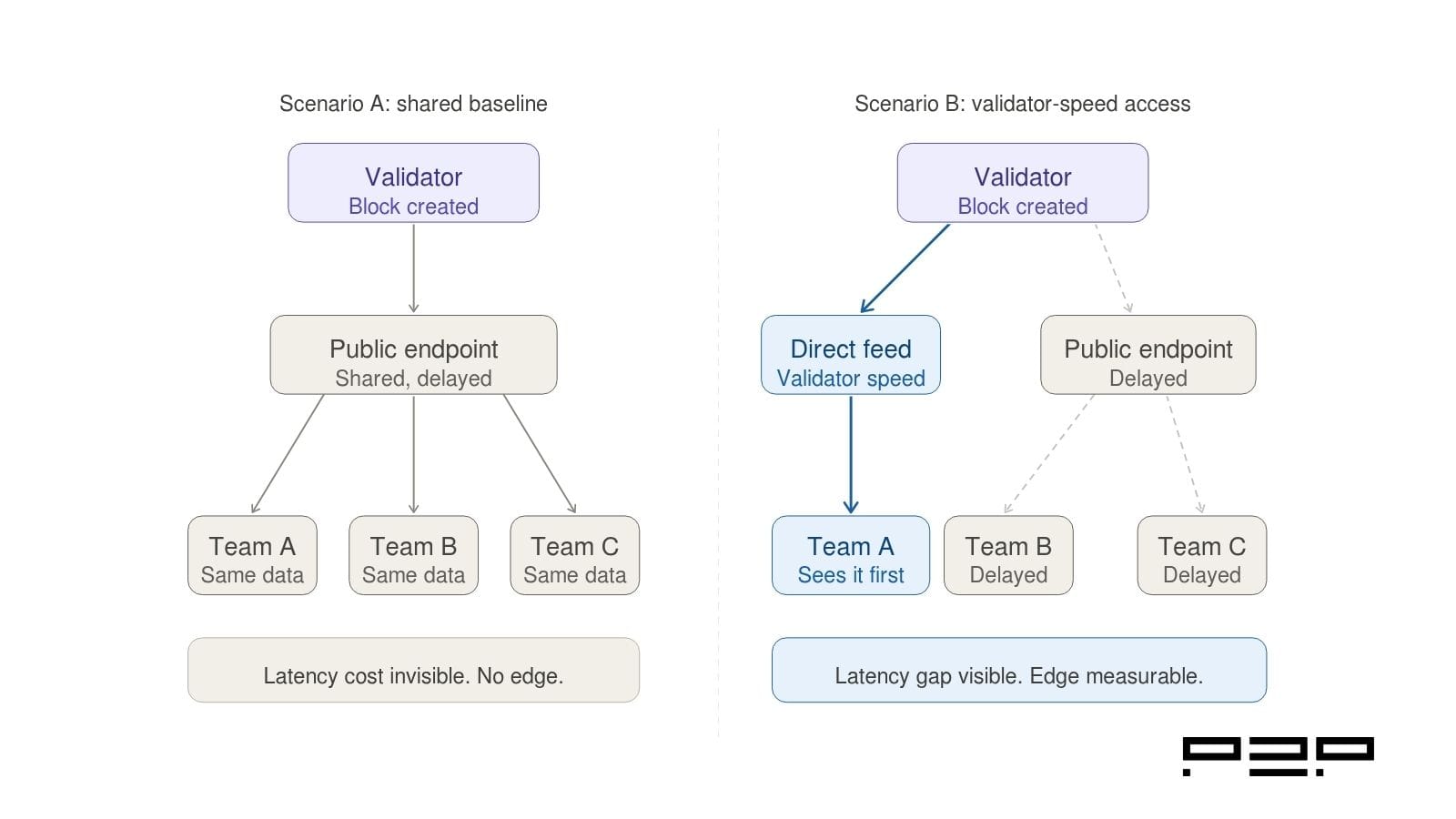
The reason most teams do not notice this cost is straightforward: everyone is using the same infrastructure.
When trading teams and market makers are all consuming data from the same public endpoints, on-chain data latency becomes a shared condition rather than a competitive disadvantage. No individual team feels the pain acutely because no individual team has a faster alternative to compare against.
This is the baseline problem. The loss is real, but it is diffuse. It shows up as strategies that should work in theory but underperform in practice. It shows up as fill rates that are slightly worse than expected. It shows up as opportunities that seem to close just before your orders land.
Teams attribute these outcomes to market conditions, strategy parameters, and execution quality. Rarely to data infrastructure. Because the data infrastructure question was never asked.
The question only gets asked when a team benchmarks against a faster feed and sees the gap directly.
The cost of on-chain data latency is invisible when every team is on the same baseline. It only becomes measurable when one team has faster access for comparison.
What the gap looks like in practice
On Sui, transaction events surface at public checkpoints after the network has processed and propagated them. A team consuming data from a public RPC is seeing the network state as it was, not as it is. On a chain where validators process transactions in single-digit milliseconds at the certificate processing stage, the gap between what a validator knows and what a public endpoint delivers is measured in tens of milliseconds. That is enough time for multiple state changes to occur.
On Hyperliquid, the dynamic is sharper. The public API delivers order book data at approximately 260 ms, with snapshots only, rate-limited to 100 requests per minute*. For a market maker or quant fund trying to model counterparty flow, that feed is not just slow. It is structurally limited in important ways. Snapshot-based delivery without user attribution makes it difficult to conduct entire classes of signal research on public infrastructure.*
The teams that have moved to validator-speed real-time blockchain data streams on these networks are not just faster. They are operating with a fundamentally different information set.
Why this is a business problem, not a technical problem
On-chain data latency is easy to frame as an infrastructure concern. For execution-critical teams, it is a bottom-line concern.
For MEV searchers on Sui, being 15 ms* behind the fastest available feed means running strategies against a state that has already been acted on. Every search that resolves to a closed opportunity is a search that costs gas and returns nothing. The latency is not a technical inefficiency. It is a direct cost per failed search.
For market makers on Hyperliquid, quoting on stale orderbook data means setting spreads that do not reflect current conditions. A market maker quoting on data that is 200 ms* old on a venue that moves in 100 ms* intervals is not providing liquidity. They are subsidising better-informed counterparties with tighter access to the same data.
For arbitrage desks operating across pairs or venues, the window for a viable round-trip closes as soon as faster participants act on the same signal. On-chain data latency determines whether you see that signal in time to act, or whether you see it after the round-trip is already unviable. In each case, the latency cost is not a line item. It is embedded in the gap between theoretical and realised returns. It is hard to surface without a faster point of comparison.
When the cost becomes visible
The cost of on-chain data latency only becomes visible through comparison. And the comparison only becomes possible when a faster alternative exists and is accessible.
For most of the history of on-chain trading on Sui and Hyperliquid, accessible, documented, validator-speed data feeds have been hard to come by, particularly for teams without institutional-scale infrastructure budgets. The barrier to entry was high enough that most teams never made the comparison.
That is changing. Validator-speed real-time blockchain data streams are now available at flat monthly pricing, with free trials designed to make comparisons easy. The benchmark is the product. Run it alongside your existing feed. Measure the gap. Decide whether the edge is worth the cost.
For most execution-critical teams, the answer becomes clear quickly.
The infrastructure principle behind the edge
The latency advantage of validator-speed data comes from one architectural decision: sourcing data at the point of origin rather than consuming it downstream.
Public endpoints are downstream consumers of validator output. They receive data after it has propagated through the network, been confirmed, and been made available to shared infrastructure. The delay is structural. It cannot be optimised away by tuning polling intervals or upgrading RPC tiers. It is inherent to the architecture.
A real-time blockchain data stream sourced directly from an active validator node eliminates that structural delay. On Sui, this means surfacing transaction events at certificate processing, before public checkpoints. On Hyperliquid, this means reading order flow data directly from disk files on private Sentry infrastructure that peers with the validator over a private network, before block data propagates publicly.
The result is not incremental improvement on the same architecture. It is a different position entirely in the data delivery chain.
What to do with this
If your team is operating on Sui or Hyperliquid and has never benchmarked your data feed against validator-speed delivery, the first step is straightforward: run the comparison.
Syncro Data Stream by P2P.org is a real-time blockchain data stream for Sui and Hyperliquid, built directly on P2P.org’s active validator infrastructure. New clients receive a one-week free trial to validate latency and data quality against their existing setup. No credit card required.
The trial is designed to answer one question: how much latency is your current feed adding, and does it matter for how you operate?
Check the full technical documentation for Sui Data Stream here and Hyperliquid here.
P2P.org has operated blockchain infrastructure since 2018 across 40+ proof-of-stake networks, serving 190+ institutional partners. Syncro is P2P.org’s crypto trading infrastructure product line, built on active validator nodes across Solana, Sui, and Hyperliquid.
Disclaimer
This material is provided for informational purposes only and does not constitute investment, financial, legal, or tax advice. P2P.org accepts no liability for any actions taken based on it. Latency and performance figures referenced are estimates based on internal benchmarks and may vary depending on network conditions, geography, and client infrastructure. Past performance is not indicative of future results.
Subscribe to P2P-economy
Get the latest posts delivered right to your inbox
<hr><h2 id="series-institutional-lens"><strong>Series:</strong> Institutional Lens</h2><p>The Institutional Lens series examines protocol mechanics, infrastructure decisions, and governance considerations for institutions participating in proof-of-stake networks. It is written for professionals operating at the intersection of traditional finance and blockchain infrastructure.</p><p><strong>Previously in the series:</strong> <a href="https://p2p.org/economy/how-to-build-an-institutional-staking-program-across-multiple-networks/">How to Build an Institutional Staking Program Across Multiple Networks</a></p><hr><h2 id="learnings-for-busy-readers">Learnings for Busy Readers</h2><p>Article 3 in this series established the framework for designing a multi-network institutional staking program. This article addresses the governance layer that the program creates.</p><p>Most institutions have a policy for how they vote their equity holdings. Almost none have a policy for how they govern their staked network positions. That gap is closing, and closing fast.</p><p>Here is what this article covers and why it matters now:</p><ul><li>When you stake on a proof-of-stake network, you typically acquire governance rights over that network. Those rights do not disappear because you did not ask for them.</li><li>Governance models differ materially across networks. On Cosmos, delegators vote independently of their validators. On Polkadot, staking and governance are structurally separate. On Ethereum, governance is off-chain and informal. These differences require network-specific policies, not a single blanket approach.</li><li>Governance decisions on PoS networks are consequential. In March 2026, Polkadot token holders voted to cut annual issuance by 53.6% and set a hard supply cap for the first time. Every institutional DOT holder was affected. Governance is not a theoretical concern.</li><li>For custodians managing assets on behalf of clients, ETF issuers with staking-integrated products, and regulated funds with fiduciary obligations, undocumented governance participation is an operational and compliance gap.</li><li>The practical path forward is a documented governance participation policy that covers every network in the program and is calibrated to each network's governance model.</li></ul><h2 id="why-staking-governance-rights-are-an-institutional-issue-now">Why Staking Governance Rights Are an Institutional Issue Now</h2><p>For most of the history of institutional participation in crypto, governance was a secondary concern. Institutions held Bitcoin, which has no formal governance mechanism. When they moved into Ethereum, governance was informal and off-chain, requiring no direct action from holders. The governance question was easy to defer.</p><p>That deferral is no longer sustainable for three reasons.</p><h3 id="first-the-asset-universe-has-expanded">First, the asset universe has expanded.</h3><p>The March 17, 2026, joint interpretive release by the SEC and CFTC classified 16 digital assets as commodities, removing the legal barrier that had restricted most institutional staking programs to Ethereum. Institutions are now building staking programs across Solana, Polkadot, Cosmos, Cardano, and other networks. Every one of those networks has a governance system. In many proof-of-stake protocols, stakers gain governance rights, enabling them to vote on protocol upgrades, policy changes, and treasury allocations. For institutional participants with fiduciary obligations, this creates a new category of governance responsibility.</p><h3 id="second-governance-decisions-are-financially-consequential">Second, governance decisions are financially consequential.</h3><p>This is no longer a theoretical point. In March 2026, via OpenGov referendums, Polkadot cut annual DOT issuance by 53.6%, reducing it from roughly 120 million to 55 million DOT per year. A hard supply cap of 2.1 billion DOT was set for the first time. That decision was made by token holders exercising governance rights. Institutions that held staked DOT were affected whether they participated in the vote or not. Abstaining from governance does not mean being exempt from its outcomes.</p><h3 id="third-fiduciary-standards-are-evolving">Third, fiduciary standards are evolving.</h3><p>In 2026, governance tokens are attracting significant attention from traditional finance. Major asset managers have begun acquiring governance tokens at scale to gain influence over on-chain credit infrastructure. As institutional governance participation becomes normalized, the question of whether a regulated entity has a documented policy for its on-chain governance activity is becoming a standard part of operational due diligence. Custodians managing assets on behalf of clients, and ETF issuers whose products hold staked positions, are the most exposed to this scrutiny.</p><h2 id="how-staking-governance-rights-work-across-networks">How Staking Governance Rights Work Across Networks</h2><p>The first obstacle to building an institutional governance policy is that staking governance rights does not work the same way across networks. The model varies significantly depending on whether the network uses direct token-holder voting, delegation, conviction voting, or representative governance. Understanding the model for each network in your program is a prerequisite to having any coherent policy.</p><h3 id="ethereum">Ethereum</h3><p>Ethereum's base-layer governance is off-chain and informal. Protocol changes are proposed through Ethereum Improvement Proposals, debated in public forums, and implemented by client teams. There is no formal on-chain voting mechanism for base-layer changes. Validators participate in consensus but do not have a formal governance vote on protocol upgrades.</p><p>For institutional operators, this means Ethereum governance participation is primarily a monitoring obligation rather than an active voting requirement. The relevant question is whether protocol upgrade proposals that could affect validator behavior, reward mechanics, or slashing conditions are being tracked and evaluated.</p><p>However, Ethereum's governance picture changes in the context of liquid staking. Protocols built on Ethereum, including liquid staking protocols and DeFi vaults, have their own on-chain governance mechanisms. Institutions holding governance tokens associated with those protocols do have formal voting rights.</p><h3 id="polkadot">Polkadot</h3><p>Polkadot's OpenGov system is one of the most technically sophisticated on-chain governance mechanisms in proof-of-stake. OpenGov features enhanced delegation, allowing users to delegate their votes to trusted experts across specific governance tracks, and simultaneous referendums, enabling multiple proposals to progress at once for faster decision-making.</p><p>A critical structural point for institutional operators: on Polkadot, governance and staking are completely disjoint. Nominating a validator does not assign any governance voting rights to the validator. DOT holders vote directly in governance, separately from their staking activity. This means that delegating to a validator does not delegate governance representation. Institutions holding DOT retain their governance rights regardless of their staking configuration, and must exercise or consciously decline those rights independently.</p><p>OpenGov further allows DOT holders to delegate their voting power based on the track of a proposal, enabling specialized delegation to trusted experts for specific governance domains rather than blanket delegation to a single representative.</p><p>The March 2026 issuance vote illustrates the stakes. A governance decision that reduced annual DOT issuance by more than half and introduced a permanent supply cap was executed entirely through this mechanism. Institutions that were unaware of the vote or had no policy for participation experienced the outcome without any input.</p><h3 id="cosmos">Cosmos</h3><p>Cosmos governance operates through on-chain proposals where token holders vote directly. The key structural difference from Polkadot is the default delegation behavior. In Cosmos, if a delegator abstains from a vote, the validator they delegate to assumes their voting power. </p><p>This has a direct institutional implication. If an institution staking ATOM does not actively vote on a governance proposal, its voting power is automatically cast by its validator. This is governance by default, not by choice. For custodians managing assets on behalf of clients, and for regulated funds with voting policies, this default mechanism requires an explicit decision: either participate actively in every governance vote, or make an informed and documented choice to delegate governance representation to the validator.</p><p>Cosmos governance covers a wide range of decisions including protocol upgrades, community pool spending, parameter changes, and interchain security arrangements. The frequency and breadth of governance activity on Cosmos chains is typically higher than on Ethereum base-layer governance.</p><h3 id="cardano">Cardano</h3><p>Cardano's Voltaire governance framework, activated in 2025, introduced on-chain governance through a delegated representative model. ADA holders can delegate their governance rights to Delegated Representatives, or DReps, who vote on their behalf. Alternatively, holders can vote directly.</p><p>Governance decisions under Voltaire include protocol parameter changes, treasury withdrawals, and constitutional amendments. For institutions holding staked ADA, Voltaire creates an explicit governance participation obligation that did not exist under earlier versions of the protocol.</p><p>The structural difference from Cosmos is that ADA's governance delegation is separate from its staking delegation. Delegating to a stake pool does not automatically assign governance rights to the pool operator. Institutions must separately decide how to handle governance delegation through the DRep mechanism.</p><h3 id="solana">Solana</h3><p>Solana does not currently have a formal on-chain governance mechanism for base-layer protocol decisions. Governance is handled off-chain through validator coordination and community processes. For institutional operators, the governance obligation on Solana is primarily monitoring: tracking validator and foundation proposals that could affect protocol behavior.</p><p>This may change as Solana's governance infrastructure matures. Institutions building multi-network programs should treat Solana governance as a watch item rather than an active obligation for now.</p><figure class="kg-card kg-image-card kg-card-hascaption"><img src="https://p2p.org/economy/content/images/2026/06/Staking-Governance-Rights-by-Network.jpg" class="kg-image" alt="Comparison table showing how staking governance rights work across Ethereum, Polkadot, Cosmos, Cardano, and Solana, including default voting behavior and key institutional implications for each network." loading="lazy" width="1600" height="900" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/Staking-Governance-Rights-by-Network.jpg 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/Staking-Governance-Rights-by-Network.jpg 1000w, https://p2p.org/economy/content/images/2026/06/Staking-Governance-Rights-by-Network.jpg 1600w" sizes="(min-width: 720px) 720px"><figcaption><i><em class="italic" style="white-space: pre-wrap;">Staking Governance Rights by Network</em></i></figcaption></figure><h2 id="the-four-governance-participation-decisions-every-institution-must-make">The Four Governance Participation Decisions Every Institution Must Make</h2><p>Building an institutional governance policy for staking positions requires four explicit decisions for each network in the program.</p><h3 id="">,</h3><p>The first decision is whether the institution will vote directly on governance proposals or delegate that authority to a representative.</p><p>Direct participation requires monitoring governance proposals across every network in the program and developing internal views on how to vote. For institutions operating across five or more networks, this is a meaningful operational commitment.</p><p>Delegation to validators or governance representatives is the lower-friction path, but it is not a governance-free path. Delegating governance to a validator is a governance decision that requires documentation. For custodians and regulated funds, "we delegated to our validator, and they voted on our behalf" is an answer that requires written policy to support it, not just an operational default.</p><h3 id="decision-2-which-proposals-require-internal-escalation">Decision 2: Which Proposals Require Internal Escalation</h3><p>Not all governance proposals carry the same weight. Routine parameter adjustments are different from decisions that materially affect issuance rates, reward mechanics, or slashing conditions.</p><p>Institutional governance policies should define a threshold for escalation: which categories of proposal require internal review before the institution's governance position is determined, and which can be handled through standing delegation or default behavior.</p><p>For regulated entities, proposals that could affect the value, liquidity, or risk profile of staked positions held on behalf of clients are typically the category that requires internal escalation. The March 2026 Polkadot issuance vote falls clearly into this category. A routine parameter adjustment may not.</p><h3 id="a">a </h3><p>How governance participation is documented is not a secondary concern. For custodians managing staked assets under fiduciary obligations, governance decisions are part of the record of how the asset was managed. For ETF issuers, governance activity on staked holdings may become a disclosure obligation as regulatory frameworks mature.</p><p>At a minimum, institutional governance documentation should record:</p><ul><li>Which networks does the program participate in governance for?</li><li>The standing policy for each network (direct vote, delegation, or monitored abstention).</li><li>The internal escalation threshold for material proposals.</li><li>A log of governance votes cast or delegation decisions made, by network and proposal.</li></ul><h3 id="decision-4-counterparty-alignment">Decision 4: Counterparty Alignment</h3><p>For institutions that delegate governance to validators or governance representatives, counterparty alignment matters. The institution's governance representative will vote on its behalf. If that representative votes contrary to the institution's interests or values, the institution has no recourse after the fact.</p><p>Validator selection and governance representative selection should be evaluated together, not separately. For Cosmos networks, where the validator default vote assumption is active, this is especially important. For Polkadot, where governance and staking are disjoint, the governance delegation decision is entirely separate from the validator nomination decision and requires its own evaluation.</p><h2 id="the-governance-monitoring-obligation">The Governance Monitoring Obligation</h2><p>Even institutions that choose a passive governance posture, delegating all voting to validators or representatives, carry an ongoing monitoring obligation. Governance decisions on PoS networks can be consequential and fast-moving.</p><p>The practical monitoring framework for a multi-network staking program includes:</p><h3 id="protocol-upgrade-monitoring">Protocol upgrade monitoring</h3><p>Major protocol changes on any network in the program should be reviewed for their potential impact on validator behavior, slashing conditions, reward mechanics, and unbonding parameters. The Polkadot unbonding period reduction in March 2026, covered in the previous Institutional Lens article, originated in a governance process that institutions with staked DOT should have been tracking.</p><h3 id="issuance-and-reward-parameter-monitoring">Issuance and reward parameter monitoring</h3><p>Changes to issuance rates, validator reward curves, and protocol-defined reward mechanics directly affect the economics of staked positions. The March 2026 Polkadot issuance decision is the clearest recent example, but similar decisions occur regularly across Cosmos chains and are emerging on other networks.</p><h3 id="slashing-condition-monitoring">Slashing condition monitoring</h3><p>Protocol governance can introduce or modify slashing conditions. Institutions operating validators or delegating to validators need to know when slashing rules change before those changes take effect.</p><h3 id="governance-calendar-awareness">Governance calendar awareness</h3><p>Active governance networks like Polkadot and Cosmos chains often have multiple concurrent proposals. Institutions with a direct participation policy need a tool or a service arrangement that surfaces relevant proposals before voting windows close.</p><h2 id="building-the-governance-policy-a-practical-framework">Building the Governance Policy: A Practical Framework</h2><p>For staking product managers and validator risk committees drafting or reviewing an institutional governance participation policy, the following structure covers the essential elements.</p><h3 id="scope">Scope</h3><p>The policy should name every network in the staking program and classify each by its governance model: direct token-holder voting (Cosmos), disjoint governance and staking (Polkadot OpenGov), delegated representative model (Cardano Voltaire), informal off-chain governance (Ethereum base layer, Solana).</p><h3 id="default-posture-by-network">Default posture by network</h3><p>For each network, the policy should specify whether the default posture is direct participation, delegation to the validator, delegation to a named governance representative, or monitored abstention.</p><h3 id="proposals">Proposals</h3><p>The policy should define what categories of proposals trigger internal review rather than default handling. At a minimum, issuance changes, slashing condition changes, and any proposal that materially affects the liquidity or economics of staked positions.</p><h3 id="counterparty-governance-alignment">Counterparty governance alignment</h3><p>For networks where governance is delegated, the policy should specify how governance alignment with the chosen validator or representative is evaluated and at what frequency.</p><h3 id="documentation-standard">Documentation standard</h3><p>The policy should specify the record-keeping format for governance participation: which decisions are logged, where, and in what format, so that the record is available for audit or regulatory review.</p><h3 id="review-cadence">Review cadence</h3><p>Governance frameworks on PoS networks evolve. The policy should be reviewed at least annually and updated following any material governance change on the network in the program.</p><hr><blockquote><strong>The institutional digital asset space moves fast.</strong> Our subscribers get structured analysis across staking, DeFi vaults, and regulation through <em>DeFi Dispatch</em>, <em>Institutional Lens</em>, <em>DeFi Infrastructure for Institutions</em>, and <em>Legal Layer</em>. No noise. Just the signals that matter. <strong>Subscribe to the newsletter at the bottom of this page.</strong></blockquote><hr><h2 id="governance-rights-and-the-multi-network-program-infrastructure-question">Governance Rights and the Multi-Network Program Infrastructure Question</h2><p>An institutional staking program spanning five or more networks creates a governance, monitoring, and participation burden that cannot be managed manually at scale. The operational infrastructure supporting the program needs to surface governance proposals, track voting windows, and maintain participation records across every network simultaneously.</p><p>For institutions evaluating multi-network staking infrastructure, P2P.org Hub is designed to support institutional staking program management across multiple PoS networks from a single platform. <a href="https://www.p2p.org/products/p2p-hub?ref=p2p.org">P2P.org Hub</a> provides the operational layer through which custodians, treasury teams, and staking product managers can oversee validator performance, reward tracking, and program management across their full network allocation.</p><p>For the multi-network program design framework that this governance policy sits within, see the previous Institutional Lens article: <a href="https://p2p.org/economy/how-to-build-an-institutional-staking-program-across-multiple-networks/">How to Build an Institutional Staking Program Across Multiple Networks</a>.</p><h2 id="an">an </h2><p>Staking governance rights are not optional. They exist by default when you stake, they vary materially across networks, and they produce consequential outcomes whether you participate or not.</p><p>The March 2026 Polkadot issuance decision affected every DOT holder. Governance decisions on Cosmos chains are cast by validators on behalf of delegators who do not vote. Cardano's Voltaire framework created formal governance obligations that did not exist two years ago.</p><p>Institutions that have designed multi-network staking programs without a corresponding governance participation policy have an open gap. A documented policy covering scope, default posture by network, escalation thresholds, counterparty alignment, and record-keeping is the practical path to closing it.</p><p>Staking governance rights are not a compliance burden to be minimized. They are an instrument of participation in the networks that institutional capital is increasingly supporting at scale. Treating them as such is part of operating a staking program at an institutional standard.</p><h2 id="frequently-asked-questions-faq">Frequently Asked Questions (FAQ)<br></h2><h3 id="what-are-staking-governance-rights-and-why-do-they-matter-for-institutions">What are staking governance rights, and why do they matter for institutions?</h3><p>Staking governance rights are the protocol-level rights that accrue to token holders when they stake on a proof-of-stake network. Depending on the network, these rights may include voting on protocol upgrades, parameter changes, issuance decisions, treasury allocations, and slashing condition modifications. They matter for institutions because governance decisions are consequential and financially relevant. After all, the rights exist whether or not the institution has a policy for exercising them, and because regulated entities with fiduciary obligations are increasingly expected to have documented approaches to governance participation across their asset holdings, including on-chain positions.</p><h3 id="do-staking-governance-rights-differ-across-proof-of-stake-networks">Do staking governance rights differ across proof-of-stake networks?</h3><p>Yes, materially. On Ethereum's base layer, governance is off-chain and informal, with no direct voting mechanism for token holders. On Polkadot, governance and staking are structurally disjoint: nominating a validator does not transfer any governance rights to that validator, and DOT holders vote directly and separately from their staking activity. On Cosmos, if a delegator does not vote on a proposal, the validator they delegate to assumes their voting power by default. On Cardano, the Voltaire framework introduced a delegated representative model where governance delegation is separate from staking delegation. Each model requires a different institutional policy approach.</p><h3 id="what-happened-at-polkadot-in-march-2026-that-is-relevant-to-institutional-governance">What happened at Polkadot in March 2026 that is relevant to institutional governance?</h3><p>In March 2026, Polkadot token holders voted through the OpenGov on-chain governance system to cut annual DOT issuance by 53.6%, reducing it from approximately 120 million to 55 million DOT per year, and set a hard supply cap of 2.1 billion DOT for the first time. This was the most significant economic change to the Polkadot protocol since launch. Every institutional DOT holder was affected by the outcome regardless of whether they participated in the vote. The event illustrates that governance abstention is not a neutral position on networks where governance decisions can materially affect issuance rates, liquidity, and the economics of staked positions.</p><h3 id="what-is-the-default-governance-behavior-on-cosmos-chains-if-an-institution-does-not-vote">What is the default governance behavior on Cosmos chains if an institution does not vote?</h3><p>On Cosmos chains, if a delegator does not actively vote on a governance proposal, the validator they delegate to assumes and casts that voting power on their behalf. This means institutional Cosmos positions that are not actively managed produce governance outcomes by default through the validator's voting behavior. For custodians managing assets on behalf of clients, and for funds with voting policies, this default mechanism requires either active participation in governance or an explicit and documented decision to delegate governance authority to the chosen validator.</p><h3 id="what-does-a-documented-institutional-governance-policy-for-staking-need-to-cover">What does a documented institutional governance policy for staking need to cover?</h3><p>A governance policy for an institutional staking program should cover: the scope of networks included and the governance model of each; the default posture for each network (direct participation, delegation, or monitored abstention); the escalation threshold that triggers internal review for material proposals; how counterparty governance alignment is evaluated for networks where delegation is used; the documentation and record-keeping standard for governance decisions; and the review cadence for updating the policy as governance frameworks evolve.</p><h3 id="is-governance-participation-relevant-for-etf-issuers-with-staking-integrated-products">Is governance participation relevant for ETF issuers with staking-integrated products?</h3><p>Yes. ETF issuers whose products hold staked positions inherit the governance rights associated with those positions. As staking-integrated ETF products become more common following the March 2026 regulatory shift, governance participation by ETF issuers will attract increasing scrutiny from regulators and investors. Issuers should develop documented governance participation policies that address how on-chain governance rights associated with staked holdings are managed, and whether those policies are consistent with the fund's investment mandate and fiduciary obligations.</p><hr><h2 id="about-p2porg">About P2P.org</h2><p>P2P.org builds the protection layer that sits between regulated institutions and DeFi execution environments, independently of the curators who manage allocation strategies. If you are evaluating the infrastructure requirements for a DeFi allocation program, <a href="https://p2p.org/?ref=p2p.org#form" rel="noreferrer">talk to our team</a>.</p><hr><p><strong>Disclaimer</strong></p><p>This article is provided for informational purposes only and does not constitute legal, regulatory, compliance, or investment advice. Regulatory obligations may vary depending on jurisdiction and specific business activities. Readers should consult their own legal and compliance advisors regarding applicable requirements.</p>
<hr><h2 id="series-validator-playbook">Series: Validator Playbook</h2><p>The Validator Playbook is <a href="http://p2p.org/?ref=p2p.org">P2P.org</a>'s infrastructure education series for institutional Ethereum operators. Each article addresses a specific operational, risk, or governance decision that institutional validators face. Previous articles in the series covered the <a href="https://p2p.org/economy/validator-playbook-due-diligence-framework/">due diligence framework for validator infrastructure evaluation</a>, <a href="https://p2p.org/economy/validator-playbook-ethereum-slashing-explained/">how slashing works on Ethereum</a>, <a href="https://p2p.org/economy/validator-playbook-exit-queue-dynamics-institutional-validators/">exit queue dynamics</a>, and <a href="https://p2p.org/economy/distributed-validator-technology-institutional-operators/">distributed validator technology for institutional operators</a>. This article covers validator consolidation under Pectra: what changed, what the trade-offs are, and what the consolidation decision requires from custodians, hedge funds, ETF and ETP issuers, exchanges, treasury teams, infrastructure engineers, staking product managers, and risk committees.</p><hr><h2 id="learnings-for-busy-readers">Learnings for Busy Readers</h2><ul><li>Pectra's EIP-7251 raised the maximum effective balance from 32 ETH to 2,048 ETH, meaning institutions can now hold a position that previously required 64 separate validators in a single one.</li><li>Consolidation is not reversible. Once validators are merged, the only way to reduce a position is through partial withdrawal or full exit.</li><li>The slashing exposure profile changes materially after consolidation. A single key controlling 2,048 ETH carries a different initial penalty calculation than 64 keys controlling 32 ETH each.</li><li>DVT is the prerequisite condition for safe consolidation at scale. Consolidating without distributed signing infrastructure concentrates single-point-of-failure risk precisely where it was just increased.</li><li>Institutions that consolidated within six months of Pectra's activation now account for over 11% of all staked ETH, up from approximately 2% before the upgrade.</li><li>The consolidation decision belongs in a risk committee conversation, not an infrastructure one.</li></ul><h2 id="what-pectra-actually-changed-for-institutional-operators">What Pectra Actually Changed for Institutional Operators</h2><p>The Ethereum network activated the Pectra upgrade in May 2025. Eleven Ethereum Improvement Proposals were bundled into the fork. For institutional validator operators, one of them changes the infrastructure calculus more than the rest combined.</p><p>EIP-7251 raised the maximum effective balance per validator from 32 ETH to 2,048 ETH. That is a 64x increase in the capital that a single validator key can control. The 32 ETH minimum for solo stakers remains unchanged. What changed is the ceiling.</p><p>Before Pectra, an institution staking 2,048 ETH was required to operate 64 separate validators, each with its own key, each requiring attestation duties, each contributing to the beacon chain network load. Managing that at scale meant running substantial key management infrastructure, monitoring 64 distinct signing operations, and absorbing the reporting complexity of 64 individual validator records.</p><p>After Pectra, the same 2,048 ETH can sit in a single validator. One key. One attestation stream. One record.</p><p>The operational case for consolidation is straightforward. The risk case requires more scrutiny.</p><h2 id="the-consolidation-trade-off-operational-efficiency-versus-concentrated-exposure">The Consolidation Trade-Off: Operational Efficiency Versus Concentrated Exposure</h2><p>Consolidation reduces infrastructure overhead significantly. Fewer validators means fewer attestation signatures to process across the beacon chain, lower bandwidth consumption on the peer-to-peer network, and simplified internal reporting for institutions that need validator-level records to reconcile with their portfolio management and NAV infrastructure.</p><p>For institutions operating at scale, the savings compound. Treasury teams running hundreds of validators gain cleaner position management. ETF and ETP issuers benefit from consolidated records that map more directly onto the fund-level accounting their administrators require. Staking product managers reduce the operational surface area they need to monitor.</p><p>But consolidation concentrates exposure. That concentration takes three forms that institutional risk committees need to evaluate before any migration decision is made.</p><h3 id="slashing-exposure-per-key">Slashing exposure per key</h3><p>Under Pectra, the initial slashing penalty for validators using the new MaxEB parameter is calculated at 1/4,096 of the effective balance, reduced from the prior 1/32. For a fully consolidated 2,048 ETH validator, the initial penalty is 0.5 ETH, which is actually lower than the 1 ETH initial penalty on a single 32 ETH validator under the old rules. The initial penalty is not where consolidation increases risk.</p><p>The risk that risk committees need to model is the correlation penalty. If a single infrastructure failure causes a consolidated validator to behave maliciously, the correlation penalty scales with the total ETH slashed across the network in the surrounding period. A single key failure affecting 2,048 ETH produces a far larger correlation penalty than 64 independent keys failing separately at different times. The absolute downside exposure from a correlated slashing event is materially higher for a consolidated validator than for a distributed set of independent ones.</p><h3 id="single-point-of-failure-concentration">Single-point-of-failure concentration</h3><p>Before consolidation, a key compromise or infrastructure failure affected one validator out of many. After consolidation, the same failure affects the full consolidated position. For infrastructure engineers and staking product managers, this means that the signing infrastructure protecting a consolidated validator carries a higher criticality classification than it did before.</p><h3 id="exit-and-withdrawal-mechanics">Exit and withdrawal mechanics</h3><p>Consolidation is not reversible by unmerging. With 0x02 compounding credentials, institutions can make partial withdrawals down to 32 ETH, but a large consolidated validator is structurally coarser to manage than separate positions. Hedge funds and treasury teams that may need the flexibility to reduce a position incrementally should model the exit mechanics before consolidating.</p><figure class="kg-card kg-image-card kg-card-hascaption"><img src="https://p2p.org/economy/content/images/2026/06/validator-consolidation-before-after-pectra.jpg" class="kg-image" alt="Diagram comparing 64 separate 32 ETH validators before Pectra with a single 2,048 ETH consolidated validator backed by a DVT cluster after Pectra." loading="lazy" width="1600" height="900" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/validator-consolidation-before-after-pectra.jpg 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/validator-consolidation-before-after-pectra.jpg 1000w, https://p2p.org/economy/content/images/2026/06/validator-consolidation-before-after-pectra.jpg 1600w" sizes="(min-width: 720px) 720px"><figcaption><i><em class="italic" style="white-space: pre-wrap;">How EIP-7251 changes the validator architecture for institutional Ethereum operators: 64 separate keys consolidated into a single DVT-backed validator.</em></i></figcaption></figure><h2 id="the-technical-process-what-consolidation-actually-requires">The Technical Process: What Consolidation Actually Requires</h2><p>Understanding the operational steps matters for infrastructure engineers evaluating whether their current setup supports consolidation safely.</p><p>Consolidation requires updating withdrawal credentials to the 0x02 compounding format. Validators using 0x01 credentials must upgrade the target validator's credentials before a consolidation request can be submitted. This is done by sending a signed credential change operation to the consensus layer to upgrade the target validator's credentials to 0x02. Once credentials are updated, the consolidation request is submitted with the source validator public key and the target validator public key. The source validator enters a consolidation queue. While in that queue, it continues performing attestation duties and accumulating protocol-attributed participation rewards and penalties as normal, similar to the behavior of a validator in the exit queue.</p><p>Once credentials are updated, the consolidation request is submitted with the source validator public key and the target validator public key. The source validator enters a consolidation queue. While in that queue, it continues performing attestation duties and accumulating protocol-attributed participation rewards and penalties as normal, similar to the behavior of a validator in the exit queue.</p><p>When the consolidation processes, the source validator's balance transfers to the target validator. The source is treated as exited. The target receives the combined balance and continues operating under the single key.</p><p>One operational note for institutions using staking providers: Pectra's consolidation mechanic also enables validator migration between providers without forcing an exit and re-entry through the activation queue. Custodians and treasury teams evaluating provider transitions can use consolidation to move the balance to a target validator operated by the new provider, avoiding the idle period that a full exit and re-entry would require.</p><hr><blockquote><strong>The institutional digital asset space moves fast.</strong> Our subscribers get structured analysis across staking, DeFi vaults, and regulation through <em>DeFi Dispatch</em>, <em>Institutional Lens</em>, <em>DeFi Infrastructure for Institutions</em>, and <em>Legal Layer</em>. No noise. Just the signals that matter. <strong>Subscribe to the newsletter at the bottom of this page.</strong></blockquote><hr><h2 id="dvt-as-the-prerequisite-for-institutional-consolidation">DVT as the Prerequisite for Institutional Consolidation</h2><p>The VP-04 article in this series covered distributed validator technology in depth. The consolidation decision brings the DVT question back directly.</p><p>Consolidation increases the capital value controlled by a single key. DVT distributes the signing function for that key across a cluster of independent nodes, so that no single node controls the full signing authority. The two developments are complementary precisely because consolidation creates the concentration risk that DVT is designed to address.</p><p>The Ethereum Foundation moved to this architecture in March 2026, adopting DVT-lite for its own production validator setup. For institutional operators, the sequencing is clear: DVT infrastructure should be in place before consolidation is executed at scale. Consolidating onto a single machine without distributed signing is concentrating exactly the risk that the upgrade created.</p><p>Infrastructure engineers evaluating consolidation should treat DVT readiness as a prerequisite condition in the migration checklist, not a parallel workstream.</p><p>For institutional operators looking to access Pectra's consolidation features with DVT already integrated into the validator stack, P2P.org's <a href="https://www.p2p.org/networks/pectra?ref=p2p.org">Pectra infrastructure</a> is designed for this architecture.</p><h2 id="what-institutions-should-evaluate-before-consolidating">What Institutions Should Evaluate Before Consolidating</h2><p>The consolidation decision is not a default. It is a governance question that requires deliberate evaluation across several dimensions.</p><h3 id="signing-infrastructure-maturity">Signing infrastructure maturity</h3><p>Is the current key management and remote signing setup hardened to support a higher-value key? Has failover been tested? Is DVT in place or on the near-term infrastructure roadmap?</p><h3 id="slashing-protection-coverage">Slashing protection coverage</h3><p>Does the current slashing protection setup cover the consolidated validator's parameters? Has the risk model been updated to reflect the new balance-based penalty calculation?</p><h3 id="reporting-and-nav-compatibility">Reporting and NAV compatibility</h3><p>Does internal portfolio management infrastructure handle consolidated validator records cleanly? For ETF and ETP issuers using NAV calculation infrastructure, a single consolidated validator record may simplify reconciliation. For others, the change may require reporting workflow updates.</p><h3 id="exit-flexibility-requirements">Exit flexibility requirements</h3><p>Does the institution need the ability to reduce the position in small increments? If yes, the coarser exit mechanics of a large consolidated validator may conflict with operational requirements.</p><h3 id="provider-migration-optionality">Provider migration optionality</h3><p>Is there any anticipated need to move between staking providers? If yes, consolidation's provider migration mechanism may be an advantage rather than a constraint.</p><p>Institutions that can confirm DVT readiness, updated slashing models, compatible reporting infrastructure, and no near-term requirement for fine-grained exit flexibility are in a strong position to consolidate. Institutions that cannot confirm these conditions should execute consolidation only where the operational savings clearly outweigh the risks of consolidating before those conditions are met.</p><h2 id="key-takeaway">Key Takeaway</h2><p>Pectra's EIP-7251 gave institutional Ethereum operators a meaningful infrastructure option. Validator consolidation reduces operational overhead, simplifies reporting, and unlocks auto-compounding of protocol-attributed participation rewards. For custodians, hedge funds, ETF and ETP issuers, exchanges, treasury teams, infrastructure engineers, staking product managers, and risk committees, it also concentrates slashing exposure and reduces exit flexibility in ways that require deliberate governance evaluation before any migration is executed.</p><p>The institutions best positioned to consolidate are those that have already deployed DVT infrastructure, updated their slashing risk models for balance-based penalty calculations, and confirmed that their reporting stack handles consolidated validator records. Consolidation is not a default upgrade. It is an architectural decision that belongs in a risk committee conversation.</p><h2 id="frequently-asked-questions-faq">Frequently Asked Questions (FAQ)<br></h2><h3 id="what-is-eip-7251-and-what-did-it-change-for-ethereum-validators">What is EIP-7251, and what did it change for Ethereum validators?</h3><p>EIP-7251, part of the Pectra upgrade activated in May 2025, raised the maximum effective balance per validator from 32 ETH to 2,048 ETH. Before this change, an institution staking 2,048 ETH was required to operate 64 separate validators. After EIP-7251, the same position can be held in a single consolidated validator. The 32 ETH minimum for solo stakers remains unchanged. The change also introduced auto-compounding for balances above 32 ETH for validators using 0x02 compounding credentials, and modified the exit queue mechanics from a churn limit based on validator count to a churn limit based on ETH volume per epoch.</p><h3 id="how-does-consolidation-change-slashing-exposure-for-institutional-operators">How does consolidation change slashing exposure for institutional operators?</h3><p>The initial slashing penalty under Pectra's MaxEB parameter is calculated at 1/4,096 of the effective balance. For a fully consolidated 2,048 ETH validator, that produces an initial penalty of 0.5 ETH, which is actually lower in absolute terms than the 1 ETH initial penalty on a single 32 ETH validator under the old 1/32 rule. The initial penalty is not where consolidation increases risk.</p><p>The material risk for institutional operators is the correlation penalty. If a single infrastructure failure causes a consolidated validator to behave maliciously, the correlation penalty scales with the total ETH slashed across the network in the surrounding period. A single key failure affecting 2,048 ETH produces a far larger correlation penalty than 64 independent keys failing separately at different times. Risk committees that have modeled slashing exposure as a bounded, per-key event need to update those models to account for the correlation penalty dynamic before consolidating.</p><h3 id="is-validator-consolidation-reversible">Is validator consolidation reversible?</h3><p>No. Once validators are consolidated, the source validator is treated as exited and the balance transfers to the target. There is no unmerge mechanic. Institutions can reduce a consolidated position through partial withdrawals down to 32 ETH using 0x02 credentials, or through a full exit. This makes consolidated validators coarser to manage than separate positions for operators that need fine-grained exit flexibility. The decision to consolidate should account for anticipated liquidity and exit requirements before the migration is executed.</p><h3 id="why-is-dvt-a-prerequisite-for-institutional-consolidation-at-scale">Why is DVT a prerequisite for institutional consolidation at scale?</h3><p>Consolidation increases the capital value controlled by a single validator key. If that key runs on a single machine, a hardware failure, connectivity loss, or key compromise affects the full consolidated balance. Distributed validator technology distributes the signing function across a cluster of independent nodes using threshold signing mechanics, so that no single node holds full signing authority. The Ethereum Foundation adopted DVT-lite for its own production setup in March 2026 for this reason. For institutional operators consolidating significant ETH positions, DVT readiness should be confirmed before consolidation is executed, not treated as a parallel infrastructure workstream.</p><h3 id="can-consolidation-be-used-to-switch-staking-providers-without-exiting">Can consolidation be used to switch staking providers without exiting?</h3><p>Yes. Pectra's consolidation mechanic enables balance transfer between validators without requiring a full exit and re-entry through the activation queue. Custodians and treasury teams evaluating provider transitions can use consolidation to move balances to a target validator operated by the new provider. This avoids the idle period during which a full exit and reactivation would leave the position out of the network. The target validator must use 0x02 compounding credentials to receive the transferred balance.</p><h3 id="what-credentials-are-required-before-consolidation-can-be-executed">What credentials are required before consolidation can be executed?</h3><p>Validators must use 0x02 compounding credentials for the target validator before a consolidation request can be submitted. Validators currently using 0x01 credentials must first send a signed credential change operation to the consensus layer to upgrade the target validator's credentials to 0x02. Once that credential upgrade is processed, the consolidation request can be submitted with the source and target validator public keys. The source validator enters a consolidation queue and continues performing attestation duties until the request is processed.</p><hr><h3 id="about-p2porg">About P2P.org</h3><p>P2P.org builds the protection layer that sits between regulated institutions and DeFi execution environments, independently of the curators who manage allocation strategies. If you are evaluating the infrastructure requirements for a DeFi allocation program, <a href="https://p2p.org/?ref=p2p.org#form" rel="noreferrer">talk to our team</a>.</p><hr><h3 id="disclaimer">Disclaimer</h3><p>This material is provided for informational purposes only and does not constitute investment, financial, legal, or tax advice. P2P.org accepts no liability for any actions taken based on it. Latency and performance figures referenced are estimates based on internal benchmarks and may vary depending on network conditions, geography, and client infrastructure. Past performance is not indicative of future results.</p>
 ALL
Agoric
Aptos
Auth
Avail
Avalanche
Axelar
Babylon
Bitcoin
BTC
capital flow
Cardano
Celestia
certifications
Chainlink
compliance
Cosmos
Crescent
curator
Cyberway
DAOBet
Data stream
DeFi
defi dispatch
defi infrastrcuture
defi infrastructure
defi news
defi vault
due diligence
DVT
Dymension
Economy
Education
EigenLayer
Elrond
employee
employee advocacy
employee interviews
Ethereum
Evmos
exit queue
Explain Like I'm Five
Governance
Guide
hedge fund
how to
HR
HUB series
Hyperliquid
infrastructure
institutional lens
Kava
Kusama
landing
legal layer
Lido
liquid staking
LSP
Manta
Mantle
Marlin
Matic
MiCA
Moonbeam
MultiversX
Near
Networks
News
NuCypher
Oasis
Obol
Origin
P2P Verified
Partnership
pectra
Persistence
playbook
Pocket
Polkadot
Polygon
product
products
Quicksilver
Regen
regulation
Renzo
restaking
RPC Node
Sender
Serum
slashing
Solana
SSV
SSV.Network
ALL
Agoric
Aptos
Auth
Avail
Avalanche
Axelar
Babylon
Bitcoin
BTC
capital flow
Cardano
Celestia
certifications
Chainlink
compliance
Cosmos
Crescent
curator
Cyberway
DAOBet
Data stream
DeFi
defi dispatch
defi infrastrcuture
defi infrastructure
defi news
defi vault
due diligence
DVT
Dymension
Economy
Education
EigenLayer
Elrond
employee
employee advocacy
employee interviews
Ethereum
Evmos
exit queue
Explain Like I'm Five
Governance
Guide
hedge fund
how to
HR
HUB series
Hyperliquid
infrastructure
institutional lens
Kava
Kusama
landing
legal layer
Lido
liquid staking
LSP
Manta
Mantle
Marlin
Matic
MiCA
Moonbeam
MultiversX
Near
Networks
News
NuCypher
Oasis
Obol
Origin
P2P Verified
Partnership
pectra
Persistence
playbook
Pocket
Polkadot
Polygon
product
products
Quicksilver
Regen
regulation
Renzo
restaking
RPC Node
Sender
Serum
slashing
Solana
SSV
SSV.Network