What Is a Validator Data Stream and Why Does It Matter on Sui and Hyperliquid
If you have ever wondered why some trading teams on Sui and Hyperliquid consistently see on-chain data before others, the answer is usually the same: they are not consuming from a public endpoint. They are consuming from a validator data stream.
This post explains what a validator data stream is, how it works technically, and what to look for when evaluating providers. Less pitch, more architecture. For teams where data latency is a direct trading-outcome concern, the infrastructure layer is worth understanding clearly.
What is a validator data stream?
A validator data stream is a real-time feed of on-chain data sourced directly from a validator node, delivered to subscribers before that data propagates to public infrastructure.
To understand why this matters, it helps to understand what a validator actually does. Validators are the nodes responsible for processing transactions and producing blocks. They are the first point of contact for new on-chain activity. Before a transaction appears in a public checkpoint, before it reaches a shared RPC endpoint, before any downstream service sees it, the validator has already processed it.
A validator data stream taps into that processing at the earliest possible point. Rather than waiting for data to travel through the network and become available to public consumers, a subscriber receives it directly from the validator the moment it is processed.
The result is a structural latency advantage. Not an optimized version of the same architecture. A different position in the data delivery chain.
How do public RPCs and checkpoints work?
To appreciate what a validator data stream delivers, it is worth understanding the alternative clearly.
When a trading team consumes data through a public RPC endpoint, they are consuming data that has already completed a significant journey. A validator processes a transaction. That transaction propagates through the network via gossip. Other nodes receive and validate it. It is included in a block. The block is finalized and published. A checkpoint is created. The checkpoint becomes available through public RPC infrastructure.
Each of those steps takes time. On Sui, public checkpoints reflect the network state after finalization, not at certificate processing. On Hyperliquid, the public API delivers order book snapshots at approximately 260 ms* from block creation, rate-limited to 100 requests per minute*.
Shared RPC infrastructure adds further latency on top of network propagation. Public endpoints serve many clients simultaneously. Under load, queuing and rate limiting compound the delay. A team consuming from a public endpoint during peak activity is not just delayed by network propagation. They are delayed by everyone else using the same pipe simultaneously.
For most applications, this is acceptable. For execution-critical trading, it is not.
The public RPC path adds five hops between the validator and your systems. A validator data stream reduces that to one.
How does a validator data stream work differently?
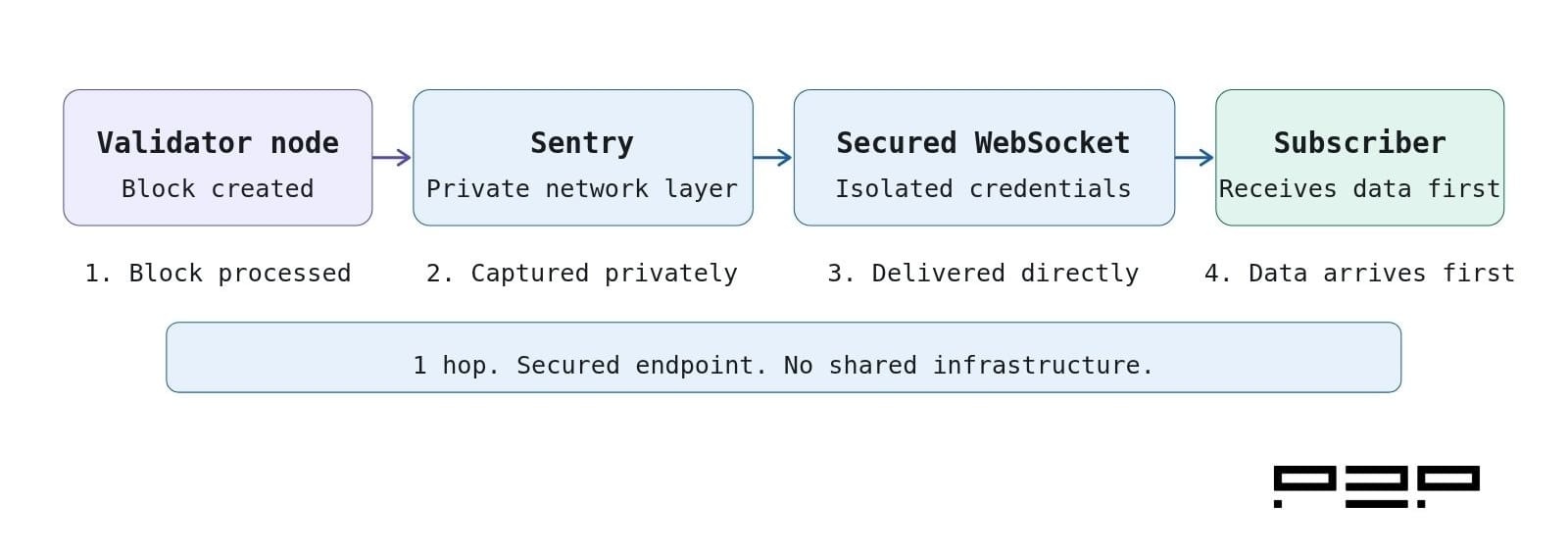
A validator data stream bypasses the propagation and shared infrastructure layers entirely by sourcing data at the point of origin.
The architecture varies slightly by network, but the core principle is consistent. The data stream runs directly on or adjacent to an active validator node. Data is captured as the validator processes it, before it enters the public propagation path, and delivered to the subscriber over a dedicated WebSocket connection with isolated credentials and IP-based access controls.
On Sui, this means capturing transaction events at certificate processing. This is the stage at which the validator has processed the transaction, but before it has been confirmed and published to the broader network. Two streaming endpoints are typically available: one covering pending transactions as they are processed, and one covering accepted transactions received from other validators before consensus. The result is the delivery approximately 15* ms ahead of public checkpoints.
On Hyperliquid, the architecture goes one step further. The data path runs from an active validator to dedicated private sentry infrastructure. The sentry node peers with the validator over a private network, receiving block data before it propagates through public gossip. Critically, the sentry reads data directly from the validator's internal output, before it passes through the node API, rather than consuming it through the node’s internal API. This eliminates an additional latency layer inherent to API-based delivery, where internal call overhead sits between the data being written and the data being sent. The result is delivery of full order flow within 115 to 135* ms of block creation.
In both cases, each subscriber receives a dedicated connection. There is no shared infrastructure, no queuing behind other clients, and no rate limiting that degrades performance under load.
What data does a validator data stream deliver?
The data surface available through a validator data stream is also meaningfully different from what public endpoints provide.
Public RPCs typically deliver snapshots: the state of the chain at a given point in time, available on request. They are built for read access, not for streaming. They do not deliver continuous event feeds, and they do not provide the granular per-event data that execution-critical strategies require.
A validator data stream delivers a continuous real-time feed of on-chain events as they occur. On Sui, this means transaction events at the moment of processing, with deduplication handled on-node. On Hyperliquid, this means the full order flow surface: every order across every asset, with order ID, side, price, quantity, status, and user attribution. Block events with height, timestamp, and apply duration. System metrics and heartbeat data on a dedicated channel, separated from the market data path so operational signals do not interfere with trading logic.
The user attribution component deserves particular attention. Aggregated public feeds do not identify the counterparty behind each order. A validator data stream that delivers user-attributed order flow enables counterparty modelling and signal research that is difficult to achieve on snapshot-based infrastructure. This is not a performance improvement. It is a meaningfully different class of data.
Why does the infrastructure layer matter for trading teams?
The trading infrastructure stack is usually discussed at the strategy and execution layer. What signals to act on? How to route orders. How to manage risk. The data layer is assumed to be a solved problem.
It is not.
The data layer determines what information is available, when it is available, and how complete it is. A strategy built on public endpoint data is constrained by the latency and completeness of that data. It is limited to acting on what has already surfaced, and to modelling counterparties it can identify. It cannot benchmark its latency because it has no faster feed to compare against.
A validator data stream changes all three constraints simultaneously. It delivers data earlier, more completely, and with attribution that public feeds do not provide.
For MEV searchers on Sui, earlier data means seeing opportunities while they are still open rather than after faster teams have closed them. For market makers on Hyperliquid, earlier and more complete data means quoting on the current state rather than the state that is already 200* ms old. For quant funds building signal pipelines, user-attributed order flow means modelling approaches that were previously unavailable.
None of these teams need to rebuild their strategies. They need to change where the data comes from.
How to evaluate a validator data stream?
Not all validator data streams are equal. A few things are worth checking before committing to a provider.
The first is whether the provider actually operates an active validator on the network in question. Some feeds marketed as validator-grade may actually route through third-party nodes. The latency advantage comes specifically from being on the validator itself, not from proximity to one. Confirm the provider operates an active validator on the relevant network before evaluating anything else.
The second is the delivery architecture. For Hyperliquid specifically, the way data is captured and delivered at the node level has a meaningful impact on latency. Architectures that minimise internal overhead between data being written and data being delivered will have an advantage at the node level. It is worth asking providers specifically how their data is captured and delivered from the validator.
The third is the operational model. A dedicated endpoint with isolated credentials and IP allowlisting is not just a security feature. It means your latency is not affected by other clients consuming the same stream. A shared endpoint, however fast the validator, reintroduces the queuing problem that public infrastructure creates.
Finally, the benchmark. Any serious validator data stream provider should offer a free trial specifically designed to let you run their feed alongside your existing setup and measure the gap directly. If the latency advantage is real, the benchmark will show it.
P2P.org has operated blockchain infrastructure since 2018 across 40+ proof-of-stake networks, serving 190+ institutional partners. Syncro is P2P.org’s crypto trading infrastructure product line, built on active validator nodes across Solana, Sui, and Hyperliquid.
Disclaimer
This material is provided for informational purposes only and does not constitute investment, financial, legal, or tax advice. P2P.org accepts no liability for any actions taken based on it. Latency and performance figures referenced are estimates based on internal benchmarks and may vary depending on network conditions, geography, and client infrastructure. Past performance is not indicative of future results.
Subscribe to P2P-economy
Get the latest posts delivered right to your inbox
<hr><h2 id="series-hub-institutional-staking">Series: Hub | Institutional Staking</h2><p>The Institutional Staking Hub is P2P.org's definitive reference for institutions building proof-of-stake programs. From foundational concepts to infrastructure selection and risk architecture, each article addresses a specific operational or technical dimension that determines how a staking program performs in practice.</p><p>Previously in the series: <a href="https://p2p.org/economy/institutional-defi-infrastructure/">Institutional DeFi Infrastructure: A Complete Guide for Funds, Custodians, and Treasury Teams</a></p><hr><h2 id="learnings-for-busy-readers">Learnings for Busy Readers</h2><p>What this article covers:</p><ul><li>What liquid staking for institutions is and how it differs from native staking.</li><li>How liquid staking tokens work and what they represent.</li><li>The capital efficiency case for institutional liquid staking programs.</li><li>The risk categories specific to liquid staking.</li><li>How LST custody and accounting differ from native staked assets.</li><li>What the regulatory treatment of liquid staking looks like in 2026.</li><li>How liquid staking integrates with ETF and ETP product structures.</li><li>A due diligence checklist for evaluating liquid staking programs.</li></ul><p><strong>The core argument</strong>: Liquid staking solves the liquidity problem of native staking by issuing a transferable token that represents a staked position. For institutions, that solution introduces a distinct risk profile, including smart contract exposure, LST depeg risk, and accounting classification complexity that requires explicit assessment before any program is designed.</p><h2 id="introduction">Introduction</h2><p>Liquid staking for institutions has moved from a capital efficiency experiment to a core operational consideration. In Q2 2025, liquid staking accounted for approximately 27% of total DeFi TVL. By August 2025, liquid staking TVL hit a record of over $86 billion, representing more than 50% of total DeFi TVL at that point. In Q3 2025, liquid staking and restaking combined represented over 45% of TVL across Ethereum equivalents. Source: <a href="https://thedefiant.io/news/defi/liquid-staking-tvl-hits-record-usd86b-amid-eth-rally-and-growing-institutional-adoption?ref=p2p.org">The Defiant</a></p><p>The regulatory environment has clarified materially. The March 2026 SEC and CFTC joint interpretation confirmed that liquid staking does not constitute a securities transaction. For compliance teams that had blocked LST exposure pending regulatory clarity, that barrier is now removed. The question shifts from whether an institution can participate to whether it should, and under what framework. Source: <a href="https://www.ropesgray.com/en/insights/alerts/2026/03/sec-and-cftc-issue-landmark-joint-guidance-on-classification-of-crypto-assets?ref=p2p.org">RopesGray</a></p><p>For custodians, funds, ETF issuers, and treasury teams, the question is now operational: what is liquid staking exactly, how do liquid staking tokens work, what are the risk categories that differ from native staking, and what does an institutional-grade liquid staking program actually require?</p><p>This article answers those questions from the ground up.</p><h2 id="what-liquid-staking-for-institutions-is">What Liquid Staking for Institutions Is</h2><p>Native staking locks capital in a proof-of-stake protocol for a defined unbonding period. On Ethereum, that period is variable but typically several days. On Solana, it is approximately four to five days. During that period, the staked capital is not accessible. It cannot be deployed elsewhere, used as collateral, or redeemed on demand.</p><p>Liquid staking solves this constraint by issuing a receipt token at the point of staking. When an institution stakes ETH through a liquid staking protocol, it receives a liquid staking token, commonly known as an LST, in return. The LST represents the staked position and accrues the protocol rewards associated with it. The LST is transferable and composable. It can be traded, used as collateral in lending protocols, deployed in DeFi allocation programs, or held as a productive asset while the underlying ETH continues to participate in consensus and accrue protocol-generated rewards.</p><p>The staked ETH remains locked in the protocol. The LST circulates freely. The institution holds capital flexibility without exiting its staking position.</p><figure class="kg-card kg-image-card kg-card-hascaption"><img src="https://p2p.org/economy/content/images/2026/06/p2p-liquid-vs-native-staking-comparison.jpeg" class="kg-image" alt="A two-panel comparison diagram. The left panel shows native staking: institution deposits ETH, ETH locks in the protocol, rewards accrue, and capital remains inaccessible until unbonding completes. The right panel shows liquid staking: institution deposits ETH, the protocol locks ETH while simultaneously issuing an LST to the institution, rewards accrue into the LST value, and capital remains transferable and deployable throughout." loading="lazy" width="1600" height="900" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/p2p-liquid-vs-native-staking-comparison.jpeg 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/p2p-liquid-vs-native-staking-comparison.jpeg 1000w, https://p2p.org/economy/content/images/2026/06/p2p-liquid-vs-native-staking-comparison.jpeg 1600w" sizes="(min-width: 720px) 720px"><figcaption><i><em class="italic" style="white-space: pre-wrap;">Native staking locks capital until unbonding completes. Liquid staking issues an LST at the point of deposit, keeping the institution liquid while the underlying asset continues participating in consensus.</em></i></figcaption></figure><p>By early 2026, major asset managers were no longer satisfied with keeping digital assets in passive cold storage, where holdings lose value against inflationary issuance. Instead, they are demanding that staking be embedded directly into their custody workflows with clear segregation of duties, auditable reporting, and strict compliance controls. Source: <a href="https://p2p.org/economy/validator-due-diligence-framework-what-institutions-really-need-to-evaluate/">P2P.org</a></p><h2 id="how-liquid-staking-tokens-work">How Liquid Staking Tokens Work</h2><p>When an institution deposits ETH into a liquid staking protocol, the protocol stakes that ETH through its validator network and issues an LST representing the deposited position. Different protocols use different LST designs.</p><h3 id="rebasing-tokens">Rebasing tokens</h3><p>These automatically adjust the holder's token balance to reflect accrued protocol rewards. If an institution holds 100 stETH and the protocol accrues rewards, the balance increases to reflect those rewards. The token price stays pegged to the underlying asset.</p><h3 id="reward-bearing-tokens">Reward-bearing tokens</h3><p>These maintain a fixed balance but appreciate in value relative to the underlying asset as protocol rewards accrue. An institution holding rETH holds a fixed number of tokens, but each token becomes redeemable for a growing quantity of ETH over time.</p><p>Both designs achieve the same economic outcome: the institution captures protocol-generated rewards while holding a liquid, transferable asset. The difference is in accounting treatment, which matters significantly for institutional reporting and tax purposes.</p><p>With 78% of institutional investors indicating interest in regulated staking derivatives, compliant liquid staking services represent a $15 billion addressable market currently underserved by existing providers. Source: <a href="https://coinshares.com/us/insights/knowledge/institutional-staking-on-the-rise/?ref=p2p.org">CoinShares</a></p><h2 id="the-capital-efficiency-case-for-institutional-liquid-staking">The Capital Efficiency Case for Institutional Liquid Staking</h2><p>The primary institutional argument for liquid staking over native staking is capital efficiency. Native staking immobilizes capital for the duration of the unbonding period. Liquid staking returns a productive, transferable asset that can be deployed further while the underlying position continues generating protocol-defined rewards.</p><p>For institutions with active treasury management programs, this changes the participation calculus. Rather than choosing between staking participation and capital availability, an institution holding LSTs captures both. The LST can serve as collateral in an approved lending protocol. It can be included in a DeFi allocation program through P2P.org's vault infrastructure, where mandate validation at the transaction level ensures every deployment remains within the institution's approved parameters. It can be held as productive collateral in structured products.</p><p>On Solana, the liquid staking ratio rose from 11.6% to 17.6% quarter-on-quarter in Q4 2025, the largest single-quarter jump on record, with ETF issuers routing assets through liquid staking protocols as a mechanism to bring protocol-generated staking rewards to investors through regulated products. Source: <a href="https://coinlaw.io/bitcoin-staking-statistics/?ref=p2p.org">CoinLaw</a></p><p>For treasury teams managing long-duration digital asset holdings, liquid staking also addresses the dilution mechanics of holding unstaked assets on networks where new tokens are continuously issued to validators and delegators. Participation offsets that dilution while preserving capital flexibility that native staking does not.</p><h2 id="the-risk-categories-specific-to-liquid-staking">The Risk Categories Specific to Liquid Staking</h2><p>Liquid staking introduces a risk profile that differs from native staking in several material ways. Each category requires explicit assessment before any institutional program is designed.</p><h3 id="smart-contract-risk">Smart contract risk</h3><p>Liquid staking protocols operate on smart contracts. The LST is issued, managed, and redeemed through protocol code. A vulnerability in that code can result in loss of capital or failure to redeem the LST for the underlying asset. This risk does not exist in native staking at the protocol layer. Institutions evaluating liquid staking must assess the audit history, code maturity, and upgrade governance of any protocol they consider.</p><h3 id="lst-depeg-risk">LST depeg risk</h3><p>An LST is only as liquid as the secondary market that trades it. Under normal conditions, LSTs trade close to the value of their underlying staked assets. Under stress conditions, that relationship can break. During the June 2022 liquidity crisis, stETH traded at approximately a 5% discount to ETH on secondary markets as withdrawal demand exceeded available liquidity, demonstrating that LSTs can decouple from their peg under stress conditions even when the underlying staking protocol remains technically solvent. This risk is structural, not idiosyncratic: any LST is subject to depeg if secondary market liquidity is insufficient to absorb redemption volume during a broad market drawdown. For custodians and funds managing redemption obligations, this is a material balance sheet consideration.</p><h3 id="custody-and-accounting-complexity">Custody and accounting complexity</h3><p>LSTs are tokens, not native staking positions. Their custody, accounting, and tax treatment differ from native staked assets and vary by jurisdiction. The treatment of LSTs for accounting, tax reporting, and regulatory classification may differ from native staked positions depending on jurisdiction. This is an active area of legal development and warrants specific advice for each institution. Institutions must confirm that their custody infrastructure supports LST holdings and that their accounting framework handles rebasing token balance adjustments and reward-bearing token appreciation correctly.</p><h3 id="protocol-concentration-risk">Protocol concentration risk</h3><p>The liquid staking market is structurally concentrated. Lido's TVL reached approximately $41 billion in August 2025, making it the leading liquid staking platform by market share. Institutions allocating through a single protocol carry significant counterparty concentration to that protocol's governance, upgrade decisions, and smart contract risk profile. Diversification across protocols is an institutional risk management consideration that does not arise in native staking.</p><h3 id="regulatory-classification-risk">Regulatory classification risk</h3><p>While the March 2026 SEC and CFTC ruling removed the primary US securities law uncertainty, the regulatory treatment of LSTs for custody obligations, capital treatment, and reporting requirements continues to evolve. In EU-regulated markets, MiCA requires licensed custodial platforms to segregate client assets from firm capital and maintain mandatory capital buffers. Institutions operating across multiple jurisdictions must assess the classification and compliance requirements for LST holdings in each operating market.</p><h2 id="lst-custody-and-accounting-in-practice">LST Custody and Accounting in Practice</h2><p>Holding an LST in an institutional context is not operationally equivalent to holding the underlying staked asset. Several dimensions require explicit design.</p><h3 id="custody-infrastructure">Custody infrastructure</h3><p>The institution's custody provider must support LST holdings at the token level. This means wallet infrastructure capable of receiving, holding, and transferring the specific token standard of each LST. Custody providers that support ETH staking natively may not automatically support LST custody at the institutional level without additional configuration.</p><h3 id="rebasing-token-accounting">Rebasing token accounting</h3><p>For institutions holding rebasing LSTs, the automatic balance adjustment that reflects accrued protocol rewards creates accounting entries that must be captured correctly. Each rebase event represents a protocol reward distribution that requires recognition for tax and reporting purposes. This differs structurally from reward-bearing tokens, which appreciate in price rather than adjusting balance.</p><h3 id="nav-calculation">NAV calculation</h3><p>For funds and ETF issuers incorporating LSTs into regulated products, net asset value calculation requires a reliable, auditable price feed for each LST held. The price relationship between an LST and its underlying asset is not always a simple 1:1 peg. Funds must have a documented methodology for LST valuation that satisfies their auditors and regulators.</p><h3 id="segregation-of-duties">Segregation of duties</h3><p>Institutions are demanding that staking be embedded directly into their custody workflows with clear segregation of duties, auditable reporting, and strict compliance controls. For liquid staking specifically, this means documented processes for LST issuance, transfer, redemption, and protocol reward recognition that satisfy both internal audit and external regulatory requirements. Source: <a href="https://p2p.org/economy/validator-due-diligence-framework-what-institutions-really-need-to-evaluate/">P2P.org</a></p><h2 id="liquid-staking-in-etf-and-etp-product-structures">Liquid Staking in ETF and ETP Product Structures</h2><p>The integration of liquid staking into regulated investment products is one of the most significant institutional developments of 2025 and 2026. ETF issuers routed assets through liquid staking protocols as a mechanism to bring protocol-generated staking rewards to investors through regulated products, with Bloomberg Intelligence ETF analyst Eric Balchunas calling Bitwise's BSOL the best ETF debut of 2025 across any asset class. Source: <a href="https://coinlaw.io/bitcoin-staking-statistics/?ref=p2p.org">CoinLaw</a></p><p>For ETF and ETP issuers, liquid staking offers a mechanism to participate in protocol reward accrual on digital asset holdings within a regulated product structure, without requiring the product to hold illiquid native staked positions. The LST is a liquid, transferable asset that can be held, valued, and redeemed within the operational constraints of a regulated fund vehicle.</p><p>Nasdaq filed a proposal in February 2026 to list the VanEck JitoSOL Solana Liquid Staking ETF, the first attempt to offer a regulated product tied directly to an LST. The product design question for ETF issuers is no longer whether to incorporate liquid staking but how to do so in a way that satisfies custody, valuation, and compliance requirements at the fund level.</p><p>For custodians supporting ETF issuers, the implication is that LST custody capability is becoming a prerequisite for institutional client retention in staking-integrated product structures.</p><h2 id="the-regulatory-treatment-of-liquid-staking-for-institutions-in-2026">The Regulatory Treatment of Liquid Staking for Institutions in 2026</h2><p>The regulatory environment for liquid staking has clarified substantially since 2025. The March 2026 SEC and CFTC joint interpretation confirmed that liquid staking does not constitute a securities transaction in the United States across all four staking models: solo, self-custodial, custodial, and liquid. The SEC's August 2025 policy statement clarified that non-managerial staking functions by providers may avoid securities classification, a position that removed a significant overhang for institutions evaluating LST exposure across proof-of-stake networks.</p><p>In Europe, MiCA provides a framework for staking within licensed digital asset service providers, with requirements for asset segregation and capital adequacy that apply to custodial platforms holding LSTs on behalf of clients. The decentralization threshold test in the CLARITY Act is the operative mechanism that institutional compliance departments will use to classify multi-chain staking programs, DeFi vault deployments, and liquid staking token arrangements going forward.</p><p>Institutions should treat the current regulatory clarity as a floor, not a ceiling. The classification of LSTs for capital treatment, tax reporting, and cross-border holding requirements continues to develop. Each institution's legal and compliance advisors must assess the applicable requirements for their specific operating markets.</p><p>Network conditions determine protocol-generated rewards and are variable. P2P.org does not control or set reward rates.</p><h2 id="where-p2porg-supports-liquid-staking-for-institutions">Where P2P.org Supports Liquid Staking for Institutions</h2><p>P2P.org operates non-custodial ETH staking infrastructure for custodians, funds, ETF issuers, and treasury teams building both native and liquid staking programs. Validator-level reward reporting and operational safeguards are available for institutional requirements. Client assets remain under the institution's control throughout.</p><p>For institutions looking to combine liquid staking positions with DeFi allocation programs, P2P.org's vault infrastructure supports LST deployment into approved protocols with mandate validation at the transaction level. Every deployment is checked against the institution's parameters before execution.</p><p>Explore P2P.org's ETH staking infrastructure at <a href="https://eth.p2p.org/staking?ref=p2p.org">eth.p2p.org/staking</a>.</p><p>Building an institutional liquid staking program? P2P.org provides non-custodial ETH staking infrastructure with validator-level reporting and operational safeguards designed for institutional requirements. <a href="https://eth.p2p.org/staking?ref=p2p.org">Explore P2P.org ETH Staking</a></p><h2 id="due-diligence-checklist-evaluating-a-liquid-staking-for-institutions-program">Due Diligence Checklist: Evaluating a Liquid Staking for Institutions Program</h2><p>For custodians, hedge funds, ETF issuers, exchanges, treasury teams, infrastructure engineers, staking product managers, and risk committees evaluating or initiating a liquid staking program, these are the foundational questions to answer before committing capital.</p><h3 id="protocol-selection">Protocol selection</h3><p>[ ] What is the audit history and code maturity of the liquid staking protocol? <br>[ ] Who governs protocol upgrades, and how are governance decisions made? <br>[ ] What is the protocol's slashing history and mechanism for covering slashing losses? <br>[ ] Is the protocol's TVL and secondary market liquidity sufficient to support institutional redemption volumes?</p><h3 id="lst-type-and-accounting">LST type and accounting</h3><p>[ ] Is the LST a rebasing token or a reward-bearing token, and does your accounting framework handle both correctly? <br>[ ] Has your accounting team confirmed the tax treatment of LST protocol reward recognition in your jurisdiction? <br>[ ] Does your NAV calculation methodology support LST valuation for fund or ETP reporting purposes?</p><h3 id="custody-infrastructure-1">Custody infrastructure</h3><p>[ ] Does your custody provider support LST holdings at the token level for the specific protocols you intend to use? <br>[ ] Is there a documented process for LST issuance, transfer, redemption, and protocol reward recognition that satisfies audit requirements? <br>[ ] Does your custody arrangement maintain asset segregation as required under MiCA or applicable regulations?</p><h3 id="risk-management">Risk management</h3><p>[ ] Has your risk committee assessed LST depeg risk and its implications for your liquidity management framework? <br>[ ] Are concentration limits defined for exposure to any single liquid staking protocol? <br>[ ] Has smart contract risk been assessed for each protocol in your approved list?</p><h3 id="regulatory-compliance">Regulatory compliance</h3><p>[ ] Has legal confirmed the regulatory treatment of LST holdings in each jurisdiction where your institution operates? <br>[ ] Does your compliance framework address the LST custody obligations applicable to your regulatory status? <br>[ ] Is there a documented policy for how LST holdings are classified and reported under your applicable accounting standards?</p><h2 id="key-takeaway">Key Takeaway</h2><p>Liquid staking for institutions solves the capital immobilization problem of native staking by issuing a transferable token that represents a staked position and continues accruing protocol-generated rewards. For custodians, hedge funds, ETF issuers, exchanges, and treasury teams, that solution introduces a distinct risk profile: smart contract exposure, LST depeg risk under market stress, custody and accounting complexity, and protocol concentration. Each of these categories requires explicit assessment and mitigation as part of any institutional liquid staking program design.</p><p>The regulatory environment in 2026 has removed the primary legal barriers to institutional participation. The infrastructure has matured to support institutional-grade programs at scale. The institutions that build a rigorous foundation across protocol selection, custody architecture, and accounting framework now will be best positioned as liquid staking becomes a standard component of digital asset strategy across every institutional segment.</p><p>Network conditions determine protocol-generated rewards and are variable. P2P.org does not control or set reward rates. Smart contract risks are protocol-defined and client-borne. Operational safeguards are implemented to reduce exposure, but do not eliminate protocol-level risk.</p><h2 id="frequently-asked-questions-faq">Frequently Asked Questions (FAQ)<br></h2><h3 id="what-is-liquid-staking-for-institutions">What is liquid staking for institutions?</h3><p>Liquid staking for institutions is a staking participation model in which an institution deposits digital assets into a proof-of-stake protocol and receives a liquid staking token in return. The LST represents the staked position, accrues protocol-generated rewards, and remains transferable and composable throughout. Unlike native staking, which locks capital for the duration of the unbonding period, liquid staking allows institutions to maintain staking participation while retaining a liquid, deployable asset. It is used by custodians, funds, ETF issuers, exchanges, and treasury teams as a capital efficiency mechanism within broader digital asset programs.</p><h3 id="what-is-a-liquid-staking-token">What is a liquid staking token?</h3><p>A liquid staking token is a receipt token issued by a liquid staking protocol when an institution deposits assets for staking. It represents the deposited position and accrues the protocol rewards associated with it. LSTs come in two primary designs: rebasing tokens, which automatically adjust the holder's balance to reflect accrued protocol rewards, and reward-bearing tokens, which maintain a fixed balance but appreciate in value relative to the underlying asset as rewards accrue. The accounting treatment of each design differs and requires explicit assessment for institutional reporting and tax purposes.</p><h3 id="how-does-liquid-staking-differ-from-native-staking-for-institutions">How does liquid staking differ from native staking for institutions?</h3><p>In native staking, capital is locked in the protocol for an unbonding period and cannot be accessed or deployed until withdrawal is complete. In liquid staking, the protocol issues an LST at the point of staking that the institution can hold, transfer, or deploy while the underlying capital remains staked and accruing protocol-generated rewards. The capital efficiency advantage of liquid staking comes with additional risk layers: smart contract exposure, LST depeg risk, and custody and accounting complexity that do not exist in native staking.</p><h3 id="what-is-lst-depeg-risk">What is LST depeg risk?</h3><p>LST depeg risk is the possibility that an LST trades at a discount to its underlying staked asset on secondary markets. Under normal conditions, LSTs trade close to parity with the underlying asset. Under stress conditions, if redemption demand exceeds available secondary market liquidity, the LST can decouple from its peg even when the underlying staking protocol remains technically solvent. This risk is structural rather than idiosyncratic and affects any LST under sufficient market stress. Custodians and funds managing redemption obligations must assess LST depeg risk as part of their liquidity management framework.</p><h3 id="what-are-the-regulatory-requirements-for-holding-lsts-institutionally-in-2026">What are the regulatory requirements for holding LSTs institutionally in 2026?</h3><p>In the United States, the March 2026 SEC and CFTC joint interpretation confirmed that liquid staking does not constitute a securities transaction. In Europe, MiCA imposes asset segregation and capital adequacy requirements on licensed custodial platforms holding LSTs on behalf of clients. The tax treatment, capital classification, and cross-border holding requirements for LSTs continue to develop across jurisdictions. Each institution's legal and compliance advisors must assess the applicable requirements for their specific operating markets before allocating.</p><h3 id="how-does-liquid-staking-fit-into-etf-and-etp-product-structures">How does liquid staking fit into ETF and ETP product structures?</h3><p>Liquid staking tokens are liquid, transferable assets that can be held, valued, and redeemed within the operational constraints of regulated fund vehicles. ETF and ETP issuers have incorporated LSTs into product structures to participate in protocol reward accrual on digital asset holdings without requiring illiquid native staked positions. The primary design considerations for ETF issuers are LST valuation methodology for NAV calculation, custody infrastructure capable of supporting LST holdings at the token level, and compliance documentation for LST classification under applicable fund regulations.</p><h3 id="what-custody-infrastructure-is-required-for-institutional-liquid-staking">What custody infrastructure is required for institutional liquid staking?</h3><p>Institutional liquid staking requires custody infrastructure capable of holding, transferring, and redeeming the specific LST token standards of each protocol used. Custody providers must support rebasing token accounting if the institution holds rebasing LSTs, with correct recognition of automatic balance adjustments as protocol reward distributions. Asset segregation as required under MiCA or applicable regulations must be maintained throughout. Institutions should confirm that their custody provider's LST support has been validated for each protocol in their approved list before committing capital.</p><hr><h3 id="about-p2porg">About P2P.org</h3><p>P2P.org builds the protection layer that sits between regulated institutions and DeFi execution environments, independently of the curators who manage allocation strategies. If you are evaluating the infrastructure requirements for a DeFi allocation program, <a href="https://p2p.org/?ref=p2p.org#form" rel="noreferrer">talk to our team</a>.</p><hr><h3 id="disclaimer">Disclaimer</h3><p>This material is provided for informational purposes only and does not constitute investment, financial, legal, or tax advice. P2P.org accepts no liability for any actions taken based on it. Latency and performance figures referenced are estimates based on internal benchmarks and may vary depending on network conditions, geography, and client infrastructure. Past performance is not indicative of future results.</p>
<p><strong>Before You Dive In:</strong></p><ul><li>Institutional staking for SOL, XTZ, and ADA is now live directly inside the Ledger Enterprise UI, with ETH integration coming soon.</li><li>The workflow runs through the standard Ledger Enterprise approval flow, so institutions can stake without changing how they already manage custody operations.</li></ul><p>The integration is non-custodial throughout: Ledger Enterprise secures the keys while P2P.org operates the validators, meaning you never relinquish control of your assets.</p><p>For most networks, institutional staking has required blind signing: signing delegation transactions outside the standard custody approval flow institutions use for everything else. </p><p>The operational risk of blind signing is one reason many institutions have not staked, despite holding assets eligible for protocol delegation.</p><p>That changes today inside Ledger Enterprise. P2P.org is now live in the platform, allowing institutional clients to delegate SOL, XTZ, and ADA directly through the standard Ledger Enterprise UI, with Clear Signing on every delegation transaction. </p><p>No raw signing involved. </p><h2 id="the-friction-this-removes"><strong>The friction this removes</strong></h2><p>Raw signing has been the default requirement for institutional delegation on most networks. The reason is structural: most validator interfaces were not designed for institutions running formal approval workflows. </p><p>Institutions that wanted to stake had to build custom procedures around raw signing, route transactions through additional internal sign-offs, and introduce additional operational complexity and approval overhead.</p><p>For institutions where every transaction is logged, reviewed, and reconciled against policy, that overhead has been a hard stop. Many simply did not stake.</p><p>Inside Ledger Enterprise, delegation transactions now move through the same approval flow institutions already use for custody. Interface, compliance steps, and audit trail are unchanged. The operational lift of starting to stake drops from building a new workflow to using the existing one.</p><figure class="kg-card kg-image-card"><img src="https://p2p.org/economy/content/images/2026/06/BLOG-P2P-x-Ledger--1-.jpg" class="kg-image" alt="" loading="lazy" width="2000" height="1125" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/BLOG-P2P-x-Ledger--1-.jpg 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/BLOG-P2P-x-Ledger--1-.jpg 1000w, https://p2p.org/economy/content/images/size/w1600/2026/06/BLOG-P2P-x-Ledger--1-.jpg 1600w, https://p2p.org/economy/content/images/size/w2400/2026/06/BLOG-P2P-x-Ledger--1-.jpg 2400w" sizes="(min-width: 720px) 720px"></figure><h2 id="what-is-live-today"><strong>What is live today</strong></h2><p><br>Three networks at launch:</p><p>-<a href="https://app.supademo.com/demo/cmoqttjvt2vwrw9don5b5mco3?ref=p2p.org"> <u>Solana: walk through the flow</u></a> </p><p>- <a href="https://app.supademo.com/demo/cmos1g2ge5024w9do49m717e5?ref=p2p.org"><u>Tezos: walk through the flow</u></a> </p><p>-<a href="https://app.supademo.com/demo/cmos2rnnk50y7w9doi1x9u6a9?ref=p2p.org"> <u>Cardano: walk through the flow</u></a></p><p>For each, the workflow is the same: clients select a P2P.org validator inside the Ledger Enterprise UI, approve the delegation transaction through the standard flow, and protocol rewards are distributed on-chain by the network. </p><p>No assets move into P2P.org's control at any point. Ledger Enterprise holds the keys throughout.</p><figure class="kg-card kg-image-card"><img src="https://p2p.org/economy/content/images/2026/06/data-src-image-52c5ead7-499d-410a-a906-40d918705948.png" class="kg-image" alt="" loading="lazy" width="1754" height="1238" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/data-src-image-52c5ead7-499d-410a-a906-40d918705948.png 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/data-src-image-52c5ead7-499d-410a-a906-40d918705948.png 1000w, https://p2p.org/economy/content/images/size/w1600/2026/06/data-src-image-52c5ead7-499d-410a-a906-40d918705948.png 1600w, https://p2p.org/economy/content/images/2026/06/data-src-image-52c5ead7-499d-410a-a906-40d918705948.png 1754w" sizes="(min-width: 720px) 720px"></figure><h2 id="what-is-coming"><strong>What is coming</strong></h2><p>ETH integration is in active development and is coming live soon. <br><br>The workflow will be the same: ETH staking support inside Ledger Enterprise, with no raw signing required. The roadmap is multi-asset by design, covering the major institutional networks under one platform with one workflow.</p><h2 id="why-p2porg"><strong>Why P2P.org? </strong></h2><figure class="kg-card kg-image-card"><img src="https://p2p.org/economy/content/images/2026/06/data-src-image-7632505b-881c-4bac-9be0-39c642b9f74b.png" class="kg-image" alt="" loading="lazy" width="1440" height="780" srcset="https://p2p.org/economy/content/images/size/w600/2026/06/data-src-image-7632505b-881c-4bac-9be0-39c642b9f74b.png 600w, https://p2p.org/economy/content/images/size/w1000/2026/06/data-src-image-7632505b-881c-4bac-9be0-39c642b9f74b.png 1000w, https://p2p.org/economy/content/images/2026/06/data-src-image-7632505b-881c-4bac-9be0-39c642b9f74b.png 1440w" sizes="(min-width: 720px) 720px"></figure><h2 id="about-the-partnership"><strong>About the partnership</strong></h2><p><strong>Sam Goh, Head of Partnerships and Strategy, Ledger Enterprise:</strong></p><p>"Institutional clients have been asking for broader native staking coverage inside Ledger Enterprise. The P2P.org integration expands that footprint with SOL, XTZ, and ADA today, ETH next, all running through the standard Ledger Enterprise approval flow without raw signing. The non-custodial setup keeps clients in control of their assets throughout."</p><p>This is the first integration between P2P.org and<a href="https://enterprise.ledger.com/?ref=p2p.org"> <u>Ledger Enterprise</u></a>, Ledger's flagship B2B SaaS platform. It builds on P2P.org's existing work with Ledger Wallet on the retail side, moving the same trust signal into institutional infrastructure. </p><p><em>Disclaimer: Staking rewards are protocol-generated, variable, and subject to network rules, validator performance, and applicable slashing or protocol risks.</em></p><h2 id="faq"><strong>FAQ</strong></h2><h3 id="which-networks-are-live-today"><strong>Which networks are live today?</strong></h3><p>SOL, XTZ, and ADA delegation is live inside the Ledger Enterprise UI as of launch.</p><h3 id="when-does-eth-go-live"><strong>When does ETH go live?</strong></h3><p>ETH integration is in active development. A separate launch announcement will follow when it is live.</p><h3 id="how-is-this-different-from-raw-signing"><strong>How is this different from raw signing?</strong></h3><p>Raw signing requires institutions to sign delegation transactions outside the standard custody approval flow, which adds operational steps and creates additional risk on every transaction. Inside Ledger Enterprise, delegation moves through the same approval workflow institutions already use for custody.</p><h3 id="who-controls-the-assets"><strong>Who controls the assets?</strong></h3><p>Ledger Enterprise holds the keys throughout. P2P.org operates the validator infrastructure on a non-custodial basis. Assets stay in the institution's control at all times.</p><h3 id="is-this-the-same-as-ledger-wallet"><strong>Is this the same as Ledger Wallet?</strong></h3><p>No. Ledger Enterprise is the institutional platform. Ledger Wallet is the retail product. P2P.org has worked with Ledger Wallet on the retail side; this integration is the first on the Enterprise side.</p><h3 id="how-do-i-get-started"><strong>How do I get started?</strong></h3><p>Existing Ledger Enterprise clients can find delegation options inside the platform UI. </p><p><strong>Talk to our institutional team about staking on Ledger Enterprise →</strong> <a href="https://calendly.com/p2p-staking-partnerships/discovery?ref=p2p.org">https://calendly.com/p2p-staking-partnerships/discovery</a> </p>
 ALL
Agoric
Aptos
Auth
Avail
Avalanche
Axelar
Babylon
Bitcoin
BTC
capital flow
Cardano
Celestia
certifications
Chainlink
compliance
Cosmos
Crescent
curator
Cyberway
DAOBet
Data stream
DeFi
defi dispatch
defi infrastrcuture
defi infrastructure
defi news
defi vault
due diligence
DVT
Dymension
Economy
Education
EigenLayer
Elrond
employee
employee advocacy
employee interviews
Ethereum
Evmos
exit queue
Explain Like I'm Five
Governance
Guide
hedge fund
how to
HR
HUB series
Hyperliquid
infrastructure
institutional lens
Kava
Kusama
landing
legal layer
Lido
liquid staking
LSP
Manta
Mantle
Marlin
Matic
MiCA
Moonbeam
MultiversX
Near
Networks
News
NuCypher
Oasis
Obol
Origin
P2P Verified
Partnership
pectra
Persistence
playbook
Pocket
Polkadot
Polygon
product
products
Quicksilver
Regen
regulation
Renzo
restaking
RPC Node
Sender
Serum
slashing
Solana
SSV
SSV.Network
ALL
Agoric
Aptos
Auth
Avail
Avalanche
Axelar
Babylon
Bitcoin
BTC
capital flow
Cardano
Celestia
certifications
Chainlink
compliance
Cosmos
Crescent
curator
Cyberway
DAOBet
Data stream
DeFi
defi dispatch
defi infrastrcuture
defi infrastructure
defi news
defi vault
due diligence
DVT
Dymension
Economy
Education
EigenLayer
Elrond
employee
employee advocacy
employee interviews
Ethereum
Evmos
exit queue
Explain Like I'm Five
Governance
Guide
hedge fund
how to
HR
HUB series
Hyperliquid
infrastructure
institutional lens
Kava
Kusama
landing
legal layer
Lido
liquid staking
LSP
Manta
Mantle
Marlin
Matic
MiCA
Moonbeam
MultiversX
Near
Networks
News
NuCypher
Oasis
Obol
Origin
P2P Verified
Partnership
pectra
Persistence
playbook
Pocket
Polkadot
Polygon
product
products
Quicksilver
Regen
regulation
Renzo
restaking
RPC Node
Sender
Serum
slashing
Solana
SSV
SSV.Network